Dans le cadre de notre formation en BUT Informatique, nous avons choisi de nous consacrer à un projet ambitieux et stimulant : l’apprentissage par renforcement (“Reinforcement Learning”). Ce domaine de l’intelligence artificielle, en pleine expansion, permet à un agent d’apprendre à prendre des décisions optimales en interagissant avec un environnement dynamique. L’agent observe son environnement, agit, reçoit une récompense, et ajuste ses actions en conséquence, créant ainsi une boucle d’apprentissage autonome.
Notre projet, intitulé « Apprentissage par renforcement, application à l’écriture d’IA jouant à des jeux d’arcade », a pour objectif d’explorer les mécanismes fondamentaux du RL. Nous nous sommes fixés comme défi de concevoir et d’entraîner des agents capables de jouer à des jeux variés, allant de jeux simplistes — où le nombre d’états est limité — à des jeux plus complexes, comme des classiques d’arcade tels qu’Arkanoid ou Tetris, voire des jeux combinatoires. Ce travail est encadré par Marin Bougeret et Victor Poupet, et s’inscrit dans une démarche à la fois théorique et pratique.
Comprendre et formaliser les algorithmes classiques d’apprentissage par renforcement : Nous avons étudié en profondeur les principes sous-jacents de ces algorithmes, leurs forces, leurs limites, et leurs propriétés mathématiques.
Découvrir les bonnes pratiques pour entraîner ces algorithmes : Cela inclut la définition des entrées adaptées pour l’agent, la conception de systèmes de récompenses efficaces, et l’optimisation des paramètres pour garantir une convergence rapide et robuste.
Explorer les arbres de recherche de Monte Carlo (MCTS) : Nous aborderons également les méthodes hybrides, comme le Monte Carlo Tree Search (MCTS), utilisé avec succès dans des applications.
Pour mener à bien ce projet, nous avons utilisé le langage Python et la bibliothèque Gymnasium. Cette librairie, spécialement conçue pour faciliter l’implémentation d’algorithmes de RL, nous a fourni les outils nécessaires pour modéliser des environnements, simuler des interactions, et évaluer les performances de nos agents. Bien que la maîtrise préalable de Python ne fût pas obligatoire, ce projet a été l’occasion d’approfondir nos compétences en programmation et en algorithmique.
Ce sujet nous a particulièrement attirés pour son aspect pluridisciplinaire, mêlant algorithmes avancés, mathématiques appliquées, et expérimentation pratique. Il offre une opportunité unique de comprendre comment les machines peuvent apprendre à résoudre des tâches complexes de manière autonome, tout en développant des compétences techniques et analytiques essentielles dans le domaine de l’IA.
installer sur le site de rust le .exe en x64 et installer rust
ensuite installer le .exe mdbook ici installer mdbook-v0.4.52-x86_64-pc-windows-msvc.zip
glisser le .exe dans l'archive directement dans le dossier mdbook de la SAE
ensuite on installe le plugin ici
il faut développer le v0.9.3-binaries et télécharger le mdbook-katex-v0.9.3-x86_64-pc-windows-gnu.zip et extraire le .exe au meme endroit que celui de mdbook
normalement si tout c'est bien fait les commandes sont les même que linux sauf que faut faire
Un processus de Markov est un processus stochastique dans lequel la prédiction du futur ne dépend que de l’état présent. Autrement dit, connaître les états passés ne rend pas la prédiction du futur plus précise : seul l’état actuel compte.
MP est défini par une fonction : MP=(S,P)
S : Un ensemble d'état fini
P : Une matrice de transition des probabilités
P : S2 -> [0, 1]
∀ s, ∑ P(s,s') = 1
S : Un nombre fini d'états
St : Un état défini par un temps t
pour simplifier, on a une fonction qui prend comme arguments s et s' et donne la probabilité de passer de l'état s à l'état s' on l'apelle Transition Probability Function.
La matrice de transition :
Si l’ensemble des états (S=s1,s2,...,sn) étant fini, on peut regrouper toutes les probabilités de transition dans une matrice de transition (P) :
P=P(s1→s1)P(s2→s1)⋮P(sn→s1)P(s1→s2)P(s2→s2)⋮P(sn→s2)⋯⋯⋱⋯P(s1→sn)P(s2→sn)⋮P(sn→sn)
Une chaîne de Markov Xi,i≥0 sur un MP(S,P) est une suite de variables aléatoires à valeurs dans S telle que pour tout i≥0 :P(Xi+1=s′∣Xi=s)=P(s,s′)
Remarque : le seul degré de liberté d'une chaîne est donc dans sa loi initiale μ0(i)=P(X0=i).
Avant les explications, il est à noter qu'il y a plusieurs types de propriétés de Markov, chacune dans des ensembles différents ou avec des conditions différentes.
Nous allons nous intéresser à la propriété de Markov dite "faible" (temps discret, espace discret) car c'est celle qui est la plus compréhensible et la plus utilisée.
On dit qu’un processus (St)t∈T vérifie la propriété de Markov si :
P(St+1=s′∣St=s,St−1=st−1,…)=P(St+1=s′∣St=s)
En GROS le futur ne dépend que du présent, les états dans lesquels nous avons été sont inutiles et n'affectent rien.
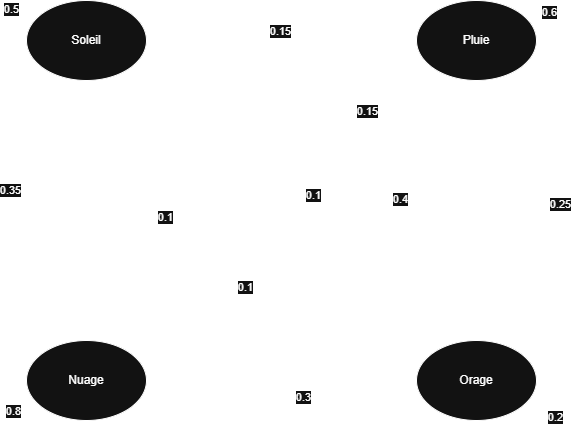
S'il fait soleil aujourd’hui, il y a 50% de chances que demain il fasse encore soleil, 15% qu'il pleuve et 35% qu'il fasse nuageux.
S’il pleut, il y a 60% de chances que demain il pleuve encore, 25% qu'il y ait des orages et 15% qu'il y ait des nuages.
S'il il y a orages aujourd’hui, il y a 10% de chances que demain il fasse ensoleillé, 40% qu'il pleuve, 20% qu'il fasse encore orageux et 30% qu'il fasse nuageux.
S'il fait nuageux aujourd’hui, il y a 10% de chances que demain il fasse ensoleillé, 10% qu'il pleuve et 80% qu'il fasse encore nuageux.
Un processus de Markov converge parfois vers une distribution stationnaireπ = π(1), ..., π(s) est telle que :
πP=πeti∑πi=1
Une distribution stationnaire est une distribution de probabilités sur les états qui reste inchangée au fil du temps.
Informellement, au départ l’état dépend de là où on démarre, mais à force de répétition les probabilités s'affinent et arrivent à un état de distribution stable
Un processus de Markov est donc un modèle où l’évolution ne dépend que de l'état actuel. Les probabilités de transition peuvent être regroupées dans une matrice et permettent d’étudier le comportement du système à long terme.
R(s) est le gain obtenu en étant dans l'état s à l'instant t
G(s) est la somme de toutes les récompenses récoltées au cours du temps.
G(s)=R(X0)+γR(X1)+γ2R(X2)+⋯+γiR(Xi)G(s)=i=0∑∞γiR(Xi)
où Xi est une chaîne de markov avec X0 = s
Remarque : G(s) est une variable aléatoire (correspondant au gain que l'on va observer en partant de s et suivant un chemin en fonction des probabilités indiquées sur les arcs)
Comme G(s) est une variable aléatoire, on ne peut pas se baser sur cette dernière
pour définir une stratégie.
Dans ce cas, on va définir V(s) qui représente le gain moyen observé en partant de l'état s
V(s)=E[G(s)]
La valeur d’un état mesure la récompense totale attendue à long terme, en partant de cet état :
Fonction Bellman_Vector_Forme(P, R, gamma):
n ← nombre de lignes de P
I ← matrice identité de taille n × n
A ← I - gamma × P
A_inv ← inverse de A
V ← A_inv × R
Retourner V
Fonction Bellman_Forme_Récursive(P, R, gamma):
V ← vecteur nul de même taille que R
seuil ← 0.0000001
max_iterations ← 10000
Pour k allant de 1 à max_iterations faire:
V_nouveau ← R + gamma × P × V
SI max(|V_nouveau − V|) < seuil alors:
Sortir de la boucle
FIN SI
V ← V_nouveau
FIN Pour
Retourner V
Pour ( R, P ) et ( γ ), on prendra les mêmes données que la forme vectorielle.
Méthode récursive :
V(s)=R(s)+γ∑P(s,s′)V(s′)
On commence la 1ʳᵉ itération avec un vecteur nul : V0(s)=(0,0)
Un Markov Decision Process (MDP) est une extension du processus de Markov dans lequel un agent peut choisir une action à chaque étape.
Le passage d’un état à un autre ne dépend donc plus uniquement de l’état actuel, mais aussi de l’action effectuée.
L’idée global par rapport a MP :
À chaque état, l’agent choisit une action.
Cette action influence la probabilité des états futurs et la récompense qu’il reçoit.
P(s,a,s′)=P(St+1=s′∣St=s,At=a) : probabilité de transition
R(s,a) : récompense immédiate reçue en faisant l’action a dans l’état s
γ∈[0,1] : facteur d’actualisation (favorise les récompenses immédiates si γ proche de 0, futures si proche de 1, en gros si on découvre ou si on joue avec nos connaissance)
Fonction Construire_MRP_Depuis_MDP(P, R, Politique):
n_etats ← nombre d'états dans P
n_actions ← nombre d'actions dans P
P_MRP ← matrice n_etats × n_etats remplie de 0
R_MRP ← vecteur de taille n_etats rempli de 0
Pour chaque état s de 0 à n_etats−1 faire:
Pour chaque action a de 0 à n_actions−1 faire:
P_MRP[s] ← P_MRP[s] + Politique[s][a] × P[s][a]
R_MRP[s] ← R_MRP[s] + Politique[s][a] × R[s][a]
FIN Pour
FIN Pour
Retourner P_MRP, R_MRP
On estime la valeur des états sous la politique courante :
Vπ(s)=R(s,π(s))+γs′∑P(s′∣s,π(s))Vπ(s′)
L’algorithme procède par itérations successives (approche approchée sur un horizon (H = 10)) :
V = {s: 0 for s in states}
for _ in range(horizon):
new_V = V.copy()
for s in states:
a = policy[s]
new_V[s] = R[(s,a)] + gamma * sum(P[(s,a)][s2] * V[s2] for s2 in P[(s,a)])
V = new_V
À la fin de cette boucle, on obtient une estimation stable de $$ (V^{\pi}) $$.
Pour chaque état (s), on calcule la valeur d’action (Q(s,a)) :
Q(s,a)=R(s,a)+γs′∑P(s′∣s,a)Vπ(s′)
et on met à jour la politique en choisissant l’action optimale :
π′(s)=argamaxQ(s,a)
Code correspondant :
for s in states:
Q_values = {}
for a in actions:
Q_values[a] = R[(s,a)] + gamma * sum(P[(s,a)][s2] * V[s2] for s2 in P[(s,a)])
policy[s] = max(Q_values, key=Q_values.get)
Value Improvement est un algorithme utilisé pour calculer la meilleure policy dans un MDP.
Il sert à déterminer quelle est la meilleure action à faire dans chaque état pour maximiser la récompense cumulée.
Pour cela Value Improvement va appliquer de manière répétée l’équation de Bellman optimale :
Vk+1(s)=αmax[R(s,a)+γs′∈S∑P(s′∣s,α)Vk(s′)]
Une fois les valeurs optimales trouvées, on en déduit la politique optimale :
Pour chaque état, on applique Bellman Optimality :
Vk+1(s)=αmax(R(s,a)+γ⋅Vk(P(s,a)))
(Note : transitions déterministes → un seul s’ possible)
Pour iteration = 1 à H :
Pour chaque état s :
valeurs_actions = liste vide
Pour chaque action a :
s' = P(s, a)
q = R(s,a) + gamma * V[s']
ajouter q à valeurs_actions
V_temp[s] = max(valeurs_actions)
V = V_temp
Une fois que les valeurs des états sont stabilisées, on choisit pour chaque état l’action qui maximise la valeur attendue :
π∗(s)=argαmax[R(s,a)+γ⋅V(P(s,a))]
Pour chaque état s :
meilleur_score = -∞
meilleure_action = null
Pour chaque action a :
s' = P(s, a)
q = R(s,a) + gamma * V[s']
Si q > meilleur_score :
meilleur_score = q
meilleure_action = a
policy[s] = meilleure_action
On applique l’équation de Bellman en boucle jusqu’à convergence.
Pseudo-code :
initialiser V(s) = 0 pour tout s
répéter
pour chaque état s :
V_new(s) = somme_a π(a|s) * somme_s' P(s'|s,a) * [R(s,a,s') + γ V(s')]
remplacer V par V_new
jusqu’à convergence
East a la valeur la plus élevée (≈ 18.868 à l’horizon 10) : c’est logique car depuis East il y a une action avec grosse récompense (anti-clock = 10) et en moyenne la politique explore cette action 1/3 du temps.
North a une valeur plus faible au départ (récompense de stay négative), mais en plusieurs étapes la valeur augmente car les transitions mènent à états plus rémunérateurs.
Les valeurs augmentent avec h (plus d’étapes = plus de récompenses accumulées, malgré le discount).
Le Monte Carlo online control est un algorithme, qui à partir des résultats récoltés, améliore la politique
de jeu actuelle, dans le but de trouver la meilleure possible.
Cet algorithme est très utile pour apprendre une politique optimale à partir des intéractions avec l'environnement, car il se
base sur son expérience. Cet algorithme est simple et possède un équilibre entre exploration et exploitation, il explore la plus part du temps
l'action la plus optimate, mais explore de temps en temps d'autres actions selon ϵ.
Il faut effectuer encore des millions d'episodes afin que l'agent puisse tout explorer et trouver la meilleur politique possible, qui donnerait le schéma suivant :
Pour utiliser l'algorithme sur cartpole-v1, Nous avons du discretiser l'espace des etats de l'environnement avec une intervalle de 12 car Cartpole possède des états continus, alors que le MCOC
nécessite des états discret.
Cartpole-v1 nous fournit les informations suivant :
Position du chariot : de -4.8 à 4.8
Vitesse du chariot : -∞ à +∞
Angle du pôle : −0.418 rad à +0.418 rad
Vitesse angulaire du pôle : −∞ à +∞
Code de l'algorithme :
def create_bins(num_bins=6):
return [
np.linspace(-4.8, 4.8, num_bins), # position
np.linspace(-5, 5, num_bins), # vitesse
np.linspace(-0.418, 0.418, num_bins), # angle
np.linspace(-5, 5, num_bins) # vitesse angulaire
]
bins = create_bins()
def discretize(state):
return tuple(int(np.digitize(s, b)) for s, b in zip(state, bins))
def MCOC(gamma, num_episodes):
env = gym.make("CartPole-v1")
# 6 bins par dimension → 6^4 = 1296 états
num_states = 6 ** 4
num_actions = env.action_space.n
k = 1
epsilon = 1
Q_values = np.zeros((num_states, num_actions))
N_visits = np.zeros((num_states, num_actions))
policy = np.ones((num_states, num_actions)) / num_actions
# --- MAIN LOOP ---
for g in range(1, num_episodes + 1):
episodes = []
rewardepisode = 0
state_cont, info = env.reset()
state = get_index(discretize(state_cont))
while True:
# best action
best_action = np.argmax(Q_values[state, :])
# remplir proba
for a in range(num_actions):
if a == best_action:
policy[state, a] = 1 - epsilon + (epsilon / num_actions)
else:
policy[state, a] = epsilon / num_actions
p = policy[state]
p = p / p.sum()
action = np.random.choice(range(num_actions), p=p)
next_state_cont, reward, terminated, truncated, _ = env.step(action)
rewardepisode += reward
next_state = get_index(discretize(next_state_cont))
episodes.append((state, action, reward))
if terminated or truncated:
break
state = next_state
# --- Monte Carlo return ---
G = {}
T = len(episodes)
G[T - 1] = episodes[T - 1][2]
for t in range(T - 2, -1, -1):
G[t] = episodes[t][2] + gamma * G[t + 1]
# --- First Visit MC ---
visited = set()
for t, (state, action, reward) in enumerate(episodes):
if (state, action) not in visited:
visited.add((state, action))
N_visits[state, action] += 1
alpha = math.sqrt(1 / N_visits[state, action])
Q_values[state, action] += alpha * (G[t] - Q_values[state, action])
# --- Policy Improvement ---
k += 1
epsilon = 1 / k
for s in range(num_states):
best_action = np.argmax(Q_values[s, :])
for a in range(num_actions):
if a == best_action:
policy[s, a] = 1 - epsilon + (epsilon / num_actions)
else:
policy[s, a] = epsilon / num_actions
print(g , rewardepisode)
return Q_values, policy
# --- Convertit un tuple d'indices (ex: (3,2,1,4)) en un index unique 0..1295 ---
def get_index(indices, num_bins=6):
i0, i1, i2, i3 = indices
return i0 * num_bins**3 + i1 * num_bins**2 + i2 * num_bins + i3
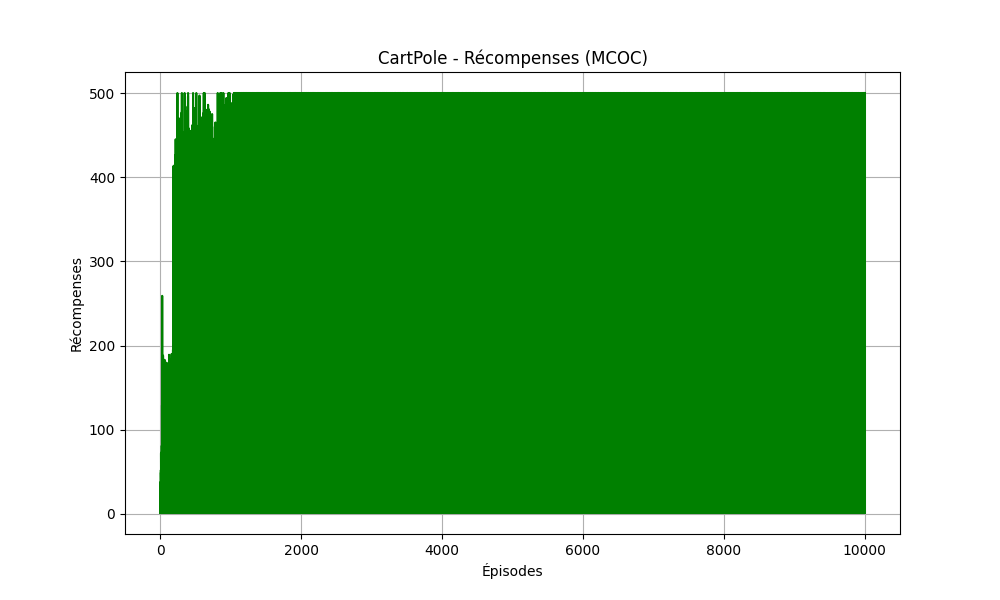
Nous avons effectué un test de 10 000 episodes sur cartpole avec cet algorithme, et cela fût un front succès. L'algorithme a atteint le reward maximal à atteindre (500), comme on peut le voir dans le graphique en dessous, l'algorithme a été constant, du 1000 ème episode jusqu'à la fin.
SARSA est un algorithme d’apprentissage par renforcement on-policy, c’est-à-dire qu’il met à jour sa fonction de state-value Q(s,a) en suivant exactement la politique utilisée pour agir.
Contrairement au Q-Learning (off-policy), SARSA apprend en évaluant les actions réellement choisies, même lorsqu'il s'agit d'un choix aléatoire (exploration).
L’acronyme signifie :
s : état actuel
a : action choisie
r : récompense reçue
s’ : état suivant
a’ : action suivante choisie par la même politique
apprendre à partir de l’expérience réelle dans l’environnement,
gérer naturellement l’exploration via ϵ-greedy,
conserver un comportement plus conservateur que Q-Learning (utile dans des environnements où des actions dangereuses mènent à des chutes rapides).
Comme il s’agit d’un algorithme on-policy, il évolue progressivement vers une politique sûre et performante tout en tenant compte des actions exploratoires.
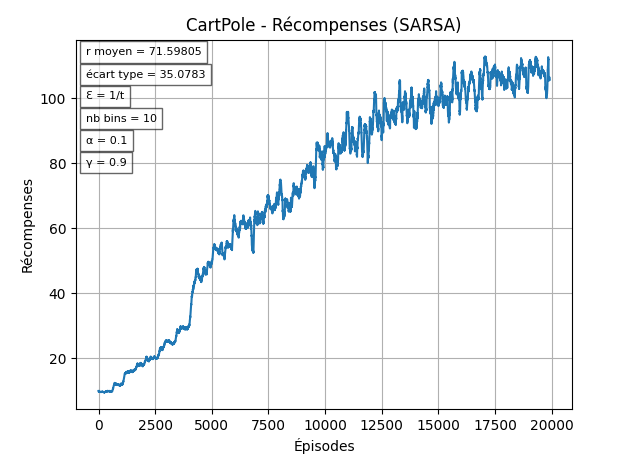
Dans cette implémentation, nous utilisons SARSA sur l’environnement CartPole-v1. Comme l’espace d’états est continu, nous devons le discrétiser avant l’apprentissage.
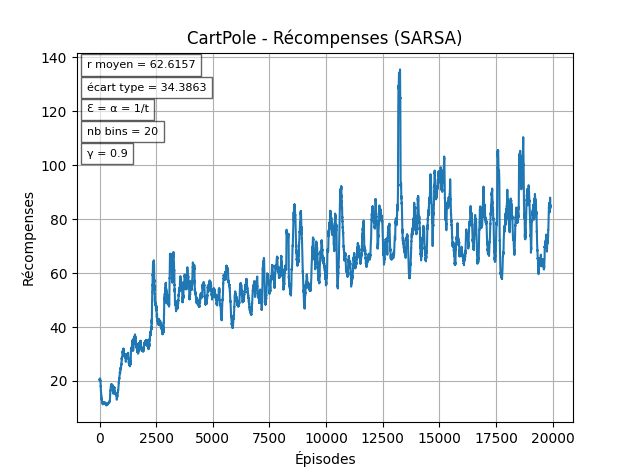
Avec les paramêtres "par défaut", les résultats obtenus sont assez faibles comparés au reward maximal de 500.
C'est notamment dû au fait que ϵ diminue très vite.
Pour cet environnement, la "résolution" (le nombre de bins) idéal pour les variables d'état semble être entre 15 et 25.
On utilisera donc 20 bins pour les prochains tests:
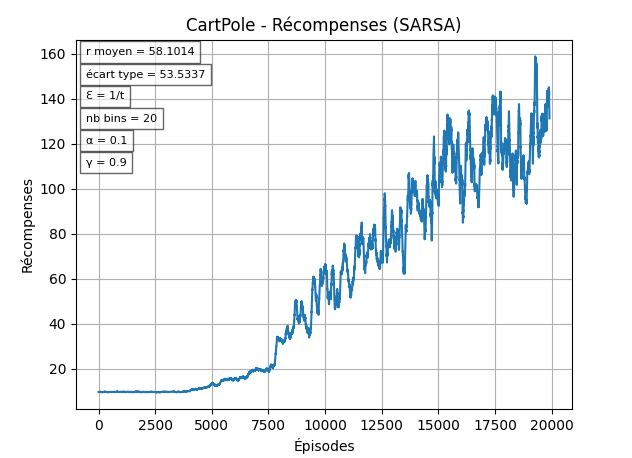
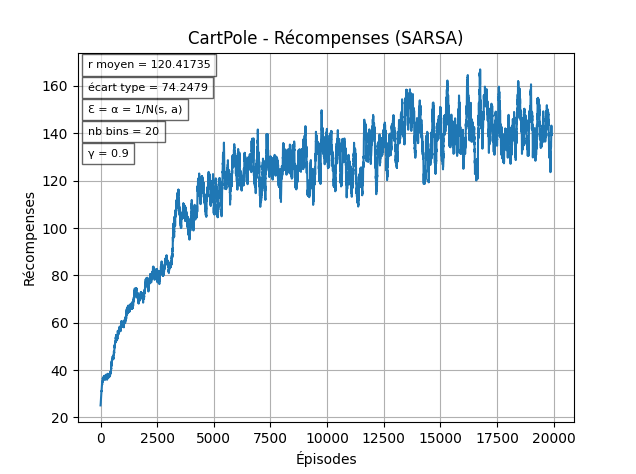
Ensuite, on veut que le taux d'apprentissage général (α) évolue au fil des épisodes pour donner plus d'importance à la politique apprise au bout d'un certains temps (sinon on risque de stagner / être ralentit à cause des choix exploratoires).
α=t1
On peut observer ici que l'agent arrive un peu plus vite à des rewards "stables".
Maintenant, on a une phase majoritairement d'exploration, et une autre pour l'exploitation, mais on continue de diminuer nos chances d'explorer sans regarder si on a déjà une "bonne" politique pour l'état.
Pour remédier à ça, on va modifier nos chances selon le nombre de visites de la paire (s,a):
ϵ=N(s,a)1α=N(s,a)1
Cette solution permet d'avoir une décroissance de l'exploration qui est spécifique à chaque paire (s,a).
Avec N(s,a) on permet à l'agent d'explorer un peu plus, ce qui affecte grandement les résulats.
Comme on peut le voir ci-dessous, il est commun que l'agent s'approche de la politique optimale, mais cela dépend encore beaucoup de l'aléatoire durant les 2000 premiers épisodes.
En résumé, SARSA est un algorithme robuste mais fortement sensible à l’initialisation stochastique : les premiers épisodes jouent un rôle déterminant, et un bon mécanisme de gestion de l’exploration (comme une décroissance dépendant des visites) peut faire toute la différence entre un apprentissage lent et la convergence vers une politique optimale.
L'élagage Alpha-Beta c'est une amélioration de l'algorithme Minimax. Le principe de base c'est de parcourir un arbre de jeu pour trouver le meilleur coup possible, mais en évitant d'explorer les branches qui ne peuvent de toute façon pas changer la décision finale. Ça permet de gagner beaucoup de temps de calcul sans changer le résultat.
Le problème avec Minimax c'est que sa complexité est exponentielle : avec un facteur de branchement b et une profondeur d, on doit évaluer O(bd) nœuds. Ça devient vite ingérable sur des jeux un peu complexes.
Alpha-Beta est utile pour :
les jeux à deux joueurs comme les Échecs ou les Dames,
les jeux à information parfaite où chaque joueur voit tout l'état du jeu,
dès qu'on a une fonction d'évaluation pour noter les états non terminaux.
Avec un bon élagage, la complexité descend à O(bd/2), ce qui revient à pouvoir chercher deux fois plus profond pour le même coût.
L'ordre dans lequel on explore les coups a beaucoup d'importance : si on regarde les meilleurs coups en premier, on génère plus de coupures et on va plus vite.
Même avec l'élagage, Alpha-Beta reste bloqué sur les jeux avec un très grand espace d'états. Au Go par exemple, le facteur de branchement est d'environ 250 avec des parties de 150 coups. Même O(bd/2) c'est bien trop lourd.
C'est pour ça qu'on s'intéresse à des algorithmes comme MCTS, qui n'essayent pas d'explorer tout l'arbre mais utilisent des simulations aléatoires pour estimer quelles branches valent la peine d'être creusées.
MCTS c'est un algorithme de recherche qui utilise des simulations aléatoires pour estimer quels coups valent la peine d'être explorés. Plutôt que de parcourir tout l'arbre de jeu comme Alpha-Beta, MCTS construit progressivement un arbre en jouant des parties aléatoires et en mémorisant les statistiques de chaque nœud. Plus on lui donne de temps, plus ses estimations sont précises.
C'est notamment grâce à MCTS que les programmes de jeu de Go ont fait un bond énorme, car Alpha-Beta est inutilisable sur ce jeu vu la taille de l'espace d'états.
Depuis ce nouveau nœud, on joue une partie entièrement aléatoire jusqu'à la fin. Ça donne un résultat z∈{−1,0,+1} selon qu'on a perdu, fait nulle ou gagné.
La différence principale c'est qu'Alpha-Beta a besoin d'une bonne fonction d'évaluation pour noter les états intermédiaires. MCTS n'en a pas besoin : il estime la valeur d'un état juste en jouant des parties aléatoires depuis cet état. C'est ce qui lui permet de s'adapter à des jeux comme le Go où écrire une bonne heuristique est très difficile.
RAVE (Rapid Action Value Estimation) est une amélioration de MCTS qui permet d'apprendre plus vite. L'idée vient de l'hypothèse AMAF (All Moves As First) : si on a joué l'action a à un moment quelconque dans une simulation, on suppose que ce résultat est aussi utile pour estimer la valeur de a depuis l'état courant.
Concrètement, on combine deux estimations :
QMC(i) : la valeur estimée par les simulations Monte Carlo classiques (lente mais fiable),
QRAVE(i) : la valeur AMAF estimée sur toutes les simulations où le coup i a été joué (rapide mais biaisée).
La combinaison MC-RAVE est :
QMC-RAVE(i)=β⋅QRAVE(i)+(1−β)⋅QMC(i)
β diminue au fur et à mesure que le nœud est visité : au début on fait plus confiance à RAVE (on a peu de données MC), et progressivement on bascule vers l'estimation MC. La formule proposée dans l'article est :
β=3Ni+kk
avec k un hyperparamètre qui contrôle à quelle vitesse on passe de RAVE à MC.
"The RAVE algorithm provides a rapid but biased estimate of action value; the Monte-Carlo algorithm provides a slower but unbiased estimate. MC-RAVE combines both estimates."
— Gelly & Silver, Monte-Carlo Tree Search and Rapid Action Value Estimation in Computer Go, Artificial Intelligence, vol. 175, n°11, 2011.
import math
import random
class Noeud:
def __init__(self, etat, parent=None):
self.etat = etat
self.parent = parent
self.enfants = []
self.N = 0 # nombre de visites
self.Q = 0.0 # somme des récompenses
def est_entierement_developpe(self, coups_legaux):
coups_explores = [e.etat.dernier_coup for e in self.enfants]
return all(c in coups_explores for c in coups_legaux)
def score_uct(self, C=1.41):
if self.N == 0:
return float('inf')
return self.Q / self.N + C * math.sqrt(math.log(self.parent.N) / self.N)
def mcts(etat_racine, n_iterations):
racine = Noeud(etat_racine)
for _ in range(n_iterations):
# --- 1. SÉLECTION ---
noeud = racine
etat = etat_racine.copie()
while not etat.est_terminal() and noeud.est_entierement_developpe(etat.coups_legaux()):
noeud = max(noeud.enfants, key=lambda e: e.score_uct())
etat.appliquer(noeud.etat.dernier_coup)
# --- 2. EXPANSION ---
if not etat.est_terminal():
coups_explores = [e.etat.dernier_coup for e in noeud.enfants]
coups_inexplores = [c for c in etat.coups_legaux() if c not in coups_explores]
coup = random.choice(coups_inexplores)
etat.appliquer(coup)
enfant = Noeud(etat.copie(), parent=noeud)
noeud.enfants.append(enfant)
noeud = enfant
# --- 3. SIMULATION (rollout) ---
etat_sim = etat.copie()
while not etat_sim.est_terminal():
coup = random.choice(etat_sim.coups_legaux())
etat_sim.appliquer(coup)
z = etat_sim.resultat() # +1, 0, ou -1
# --- 4. RÉTROPROPAGATION ---
while noeud is not None:
noeud.N += 1
noeud.Q += z
noeud = noeud.parent
# on retourne le coup le plus visité (le plus fiable statistiquement)
meilleur = max(racine.enfants, key=lambda e: e.N)
return meilleur.etat.dernier_coup
Sylvain Gelly, David Silver. Monte-Carlo Tree Search and Rapid Action Value Estimation in Computer Go. Artificial Intelligence, vol. 175, n°11, juillet 2011, pp. 1856–1876.
Nous avons utilisé en premier lieu une bibliothèque appelée Gymnasium pour développer et tester nos algorithmes d’apprentissage par renforcement. Gymnasium est une bibliothèque open-source spécialement conçue pour fournir des environnements standardisés permettant d’entraîner et d’évaluer des agents d’IA.
Avec Gymnasium, il est possible de :
Créer et manipuler des environnements variés, allant de jeux simples à des simulations plus complexes.
Tester facilement nos algorithmes grâce à une interface simple et unifiée.
Visualiser les résultats en temps réel, ce qui facilite le débogage et l’amélioration des modèles.
Cette bibliothèque nous a permis de nous concentrer sur la logique de nos agents, sans avoir à recoder les environnements de zéro. Elle est largement adoptée dans la communauté du Reinforcement Learning pour sa flexibilité et sa simplicité d’utilisation.
Le jeu Taxi est un environnement de type toy text disponible dans Gymnasium. Le but est simple :
Un taxi doit récupérer un passager à un emplacement donné, puis le déposer à une destination précise dans une grille.
Le taxi peut se déplacer dans quatre directions (nord, sud, est, ouest) et a la capacité de prendre ou déposer un passager.
L’agent reçoit des récompenses négatives à chaque action (pour encourager la rapidité) et une récompense positive lorsqu’il dépose le passager à la bonne destination.
Cet environnement est idéal pour débuter avec le Q-Learning, car il est suffisamment simple pour être compris, mais assez complexe pour illustrer les défis du Reinforcement Learning.
Le Q-Learning est un algorithme d’apprentissage par renforcement qui permet à un agent d’apprendre une politique optimale en interagissant avec son environnement. L’idée est d’apprendre une table de valeurs Q(s,a), où :
Q(s,a) représente la valeur d’une action a dans un état s.
L’agent met à jour cette table en utilisant la récompense immédiate et une estimation de la valeur future des états.
Exploration vs Exploitation : Le paramètre ϵ permet de trouver un équilibre entre découvrir de nouvelles stratégies et exploiter les connaissances acquises.
Décroissance de ϵ : ϵ diminue exponentiellement pour favoriser l’exploitation en fin d’entraînement.
Actions valides : Le masque d’actions (action_mask) évite de choisir des actions invalides dans certains états.
Le jeu CliffWalking est un environnement classique de Gymnasium.
Le but du jeu est simple, la plateau de jeu est en 4x12,
un agent doit partir d’un point de départ (case [3, 0])et atteindre l'arrivée (case [3, 11]) le plus rapidement possible tout en évitant de tomber de la falaise.
Apprendre à atteindre l'arrivée le plus rapidement possible.
Éviter les cases du qui représentent la falaise car sinon l'agent recevra une récompense négative à la hauteur -100 et devra recommencer depuis son point de départ.
Chaque déplacement de l'agent coûte une pénalité de -1.
Pour le code, on commence avec l'importation des bibliothèques.
from collections import defaultdict
import gymnasium as gym
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
Ensuite on créée une classe qui implémente le comportement de l’agent Q-Learning.
Elle gère différentes choses :
la table Q qui enregistre les valeurs Q pour chaque état et action
le epsilon-greedy qui équilibre exploration et exploitation.
La mise à jour de la table Q selon la formule du Q-Learning.
la diminution progressive de epsilon, pour réduire l’exploration au fil du temps.
class CliffAgent:
def __init__(self,
env: gym.Env,
learning_rate: float,
initial_epsilon: float,
epsilon_decay: float,
final_epsilon: float,
discount_factor: float):
self.env = env
# Table Q initialisée à zéro pour chaque état/action
self.q_values = defaultdict(lambda: np.zeros(env.action_space.n))
self.lr = learning_rate
self.discount_factor = discount_factor
# Paramètres d’exploration
self.epsilon = initial_epsilon
self.epsilon_decay = epsilon_decay
self.final_epsilon = final_epsilon
# Historique de l’erreur de mise à jour
self.training_error = []
L’agent choisit soit une action aléatoire avec la probabilité de epsilon,
on parle alors d'exploration sinon on parle d'exploitation c'est à dire que l'agent
choisiral’action la plus optimisée selon sa table Q.
À chaque interaction avec l’environnement, la valeur Q(s,a) est mise à jour
en fonction de la récompense reçue et de la valeur estimée du prochain état.
def update(self, state, action, reward, next_state, terminated):
# Estimation de la meilleure valeur future
future_q = (not terminated) * np.max(self.q_values[next_state])
# Cible de mise à jour (target)
target = reward + self.discount_factor * future_q
# Différence temporelle (TD error)
temporal_difference = target - self.q_values[state][action]
# Mise à jour de Q(s,a)
self.q_values[state][action] += self.lr * temporal_difference
# Sauvegarde de l’erreur pour analyse
self.training_error.append(temporal_difference)
Au fil des épisodes, le epsilon va diminuer pour que l’agent
se fie davantage à ce qu’il a appris.
L’agent joue chaque épisode, met à jour ses valeurs Q, puis diminue epsilon.
Chaque épisode correspond à une tentative complète pour atteindre la case d'arrivée.
rewards_per_episode = []
for episode in tqdm(range(n_episodes)):
state, info = env.reset()
done = False
total_reward = 0
while not done:
# Choix de l’action selon epsilon-greedy
action = agent.get_action(state)
# Exécution dans l’environnement
next_state, reward, terminated, truncated, info = env.step(action)
# Mise à jour des valeurs Q
agent.update(state, action, reward, next_state, terminated)
total_reward += reward
done = terminated or truncated
state = next_state
# Décroissance de epsilon à chaque épisode
agent.decay_epsilon()
rewards_per_episode.append(total_reward)
env.close()
Enfin pour évaluer la progression au cours des épisodes, on peut générer un graphique.
Voici le graphique à la fin des épisodes qu'on a fixé :
On remarque bien l'évolution où l'agent va tomber énormément de fois de la falaise et faire des mouvements
inutiles au début des épisodes car on a des récompenses de plus -5000, pour au final d'une manière exponentielle, l'agent tendra vers les -14 après au bout de 1000 épisodes.
Le jeu Acrobot est un environnement de type contrôle classique disponible dans Gymnasium. Le but du jeu est simple :
Un système à deux segments articulés (un pendule double) doit amener l’extrémité du second segment au dessus d’une certaine hauteur.
L’agent peut appliquer un couple moteur limité sur l’articulation centrale, ce qui influence le mouvement des deux segments.
L’agent reçoit des récompenses négatives à chaque étape, ce qui a pour but d'encourager l'agent à trouver la solution le plus rapidement possible.
La réussite est atteinte lorsque l’extrémité du pendule dépasse la hauteur cible (la ligne noire).
Cet environnement est idéal pour expérimenter avec des algorithmes de planification comme le MCTS, car il combine une dynamique continue avec des actions discrètes simples, tout en offrant un défi non trivial de contrôle et de planification à court et long terme.
Le Monte Carlo Tree Search (MCTS) est un algorithme de planification et d’apprentissage par simulation qui permet à un agent de choisir des actions en explorant un arbre de décisions. L’idée est d’estimer la valeur des actions en simulant des parties complètes depuis l’état courant et en utilisant ces simulations pour guider le choix :
Chaque nœud de l’arbre représente un état de l’environnement, et chaque branche correspond à une action possible.
L’agent sélectionne les actions à explorer en équilibrant exploitation (choisir les actions avec de bonnes valeurs estimées) et exploration (essayer des actions moins connues) via une formule comme UCB1 :
score=NiVi+c⋅NilnNp
où :
(Vi) : valeur cumulée du nœud (i)
(Ni) : nombre de visites du nœud (i)
(Np) : nombre de visites du parent
(c) : coefficient d’exploration
(Algorithme UCB1, réalisé en python, permettant de choisir le meilleur noeud parmis plusieurs)
def ucb1(children, c=1.0):
parent_visits = sum(child.visits for child in children.values()) + 1e-5
best_score = -float('inf')
best_child = None
for action, child in children.items():
if child.visits == 0:
score = float('inf')
else:
exploit = child.value / child.visits
explore = math.sqrt(math.log(parent_visits) / child.visits)
score = exploit + c * explore
if score > best_score:
best_score = score
best_child = child
return best_child
Après chaque simulation, la récompense finale est propagée vers le haut de l’arbre (backpropagation) pour mettre à jour les valeurs des nœuds traversés.
À la fin des itérations, l’action choisie est celle qui maximise la valeur moyenne estimée au nœud racine.
Ainsi, MCTS permet à l’agent de planifier plusieurs coups à l’avance sans connaître explicitement la dynamique de l’environnement, en s’appuyant sur des simulations pour guider ses décisions.
Cette fonction permet, à partir d'un noeud, de faire X simulations à partir du noeud de la fin du jeu.
def simulate(Inode: Node, max_steps):
total_reward = 0
env_simu = copy.deepcopy(env.unwrapped)
env_simu.state = Inode.state
steps = 0
done = False
#Tant que le programme n'a pas réussi, ou que le max_steps n'a pas été atteint, on réalise des simulations
while not done and steps < max_steps:
steps += 1
action = env_simu.action_space.sample()
obs, reward, terminated, truncated, _ = env_simu.step(action)
total_reward += reward
if terminated:
done = True
return env_simu.state, done, total_reward
La méthode backpropagate joue un rôle central dans le MCTS en permettant de remonter la récompense obtenue après une simulation à travers l’arbre de décision
def backpropagate(node: Node, reward):
while node is not None:
node.visits += 1
node.value += reward
node = node.parent
La fonction cycle représente une itération complète de MCTS à partir d’un nœud donné. Elle commence par créer les enfants du nœud si nécessaire, puis sélectionne un noeud au hasard parmi les enfants nouvellement créés. À partir de ce nœud, plusieurs simulations sont effectuées, chaque simulation produisant une récompense cumulée qui est ensuite propagée vers le haut de l’arbre grâce à backpropagate
def cycle(noeud, env):
simulate_node = noeud
all_actions = list(range(env.action_space.n))
if noeud.children == {}:
for action in all_actions:
noeud.children[action] = Node(state=copy.deepcopy(noeud.state), parent=noeud)
simulate_node = random.choice(list(noeud.children.values()))
for _ in range(random.randint(50, 100)):
final_state, done, epdone, total_reward = simulate(simulate_node, max_steps=300)
simulate_node.state = final_state
backpropagate(simulate_node, reward=total_reward)
return final_state, done, epdone, total_reward
Dans cette fonction, on rassemble tout ce que l'on a codé auparavant. On commence par initialisé le noeud racine ainsi que certaines variables.
Ensuite, dans la boucle "while", tant que le jeu n'est pas terminé, ou que les episodes ne se sont pas écoulés et que le compteur est inférieur aux nombres d'itérations choisis,
on effectue des cycles.
def mcts(env, iterations=100):
racine = Node(state=copy.deepcopy(env.unwrapped.state), parent=None)
done = False
compteur = 0
while not done and compteur < iterations:
final_state, done, epdone, total_reward = cycle(noeud=racine, env=env)
compteur += 1
print('episode :', compteur)
print('recompense actuel :', total_reward)
if done:
print('Agent a reussi')
else:
print('Agent a pas réussi')
print("Nb d'itérations :", compteur)
print("Nombre de visites racine :", racine.visits)
print("Nombre d’enfants :", len(racine.children))
return racine
Après réflexion, la réalisation d’un MCTS sur un jeu tel que Acrobot n’est pas très idéale car l’environnement possède un espace d’état continu et infini avec une dynamique physique complexe, or, le MCTS est efficace pour des espaces discret et limitées, comme le jeu de plateau Taxi. Pour ce type d’environnement, le Q-Learning est plus adapté pour apprendre une politique optimale.
Le Blackjack est un jeu de cartes où le but est de battre le croupier (dealer) en obtenant une main dont la valeur est la plus proche possible de 21, sans jamais la dépasser.
Le Monte Carlo Tree Search (MCTS) est un algorithme d’apprentissage par renforcement basé sur la simulation.
Il permet à un agent de prendre des décisions optimales en explorant un arbre de recherche et en simulant de nombreuses parties à partir des états possibles.
L’idée est d’équilibrer l’exploration (essayer de nouvelles actions) et l’exploitation (choisir les actions prometteuses déjà connues) pour estimer la meilleure décision à chaque étape.
À partir de la racine (état actuel), l’algorithme descend dans l’arbre en sélectionnant les nœuds selon une politique d’équilibre entre exploration et exploitation, à l’aide de la formule UCB1 (Upper Confidence Bound) :
UCB1=niwi+nic⋅lnN
wi : somme des récompenses du nœud i
ni : nombre de visites du nœud i
N : nombre total de simulations depuis le nœud parent
Une simulation aléatoire est exécutée à partir du nouvel état jusqu’à la fin de la partie (ou un horizon fixé).
Le résultat (victoire, défaite, score) fournit une évaluation de cet état.
Le résultat de la simulation est propagé en remontant l’arbre : chaque nœud met à jour son nombre de visites et son score moyen.
À force de répétitions, le MCTS améliore ses estimations pour chaque action.
L’action optimale depuis l’état initial est généralement celle avec le plus grand nombre de visites ou la meilleure moyenne de récompense.
Cette classe représente un état du jeu, c’est-à-dire la situation actuelle dans une partie de Blackjack : les cartes du joueur, la carte visible du croupier, et la présence éventuelle d’un as compté comme 11.
Elle contient plusieurs attributs essentiels.
L’attribut state correspond à l’état du jeu tel qu’il est fourni par l’environnement Gymnasium. visits indique combien de fois cet état a déjà été rencontré au cours des simulations. actions regroupe les deux choix possibles dans une partie de Blackjack : « stand » (Action(0)) ou « hit » (Action(1)).
Enfin, __utc_c est une constante d’exploration utilisée dans le calcul de la valeur UCB, qui permet de gérer le compromis entre exploration et exploitation.
La méthode UCB_value(self, action) calcule la valeur UCB (Upper Confidence Bound) pour une action donnée. C’est à cet endroit que se décide l’équilibre entre tester de nouvelles actions et exploiter celles qui semblent déjà prometteuses.
La méthode interne __select_action(self) choisit l’action à jouer selon les valeurs UCB ou, si l’état n’a encore jamais été visité, de manière aléatoire. Concrètement, si self.visits vaut 0, on n’a encore aucune donnée, donc l’action est tirée au hasard. Sinon, on compare les deux valeurs UCB (pour les actions 0 et 1) et on garde celle qui a la meilleure valeur. En cas d’égalité parfaite, une action aléatoire est choisie afin de conserver un minimum d’exploration.
La méthode select_learning_action(self) sert d’interface publique pour la sélection d’une action pendant la phase d’apprentissage. Elle se contente d’appeler __select_action() et applique donc la logique du MCTS avec exploration activée.
La méthode select_operating_action(self) est utilisée quand l’IA joue réellement, c’est-à-dire lorsqu’elle doit exploiter pleinement ce qu’elle a appris sans explorer. Pour cela, la constante d’exploration __utc_c est temporairement désactivée, puis l’action est choisie en fonction des valeurs moyennes observées. Une fois la sélection faite, la valeur d’origine de __utc_c est rétablie. Ce procédé permet à l’IA de prendre la meilleure décision possible à partir de son expérience accumulée.
Enfin, la méthode backtraking(self) incrémente simplement le compteur de visites de l’état (self.visits += 1). Elle est appelée à la fin de chaque simulation afin de mettre à jour l’arbre de recherche.
La classe Action représente une action possible dans une partie de Blackjack. Elle correspond concrètement au choix que l’agent peut faire à un instant donné : tirer une nouvelle carte (hit) ou s’arrêter (stand). Chaque objet Action garde en mémoire ses statistiques individuelles au fil des simulations.
Lors de son initialisation, la classe reçoit un paramètre order qui identifie l’action à effectuer dans l’environnement (0 pour stand, 1 pour hit). Trois attributs sont ensuite définis :
order, qui indique le type d’action,
visits, le nombre de fois où cette action a été jouée depuis cet état,
value, la somme totale des récompenses obtenues lorsque cette action a été choisie.
Plusieurs méthodes permettent d’accéder à ces informations. get_order() renvoie simplement le numéro associé à l’action. get_visits() retourne le nombre de fois où cette action a été essayée. get_value() donne la valeur totale accumulée grâce aux récompenses obtenues.
La méthode backtracking(self, reward) est appelée après une simulation, lorsque le résultat (ou la récompense) de l’action est connu. Elle met à jour les statistiques associées en incrémentant le compteur de visites et en ajoutant la récompense reçue à la valeur totale. C’est grâce à cette mise à jour que l’algorithme peut progressivement estimer la qualité réelle de chaque action et améliorer sa prise de décision au fil des parties.
Tout commence avec la fonction ai_training(). Celle-ci crée d’abord un environnement de jeu Blackjack grâce à la bibliothèque Gymnasium. L’utilisateur choisit ensuite combien de parties l’IA doit jouer pour s’entraîner. Ce nombre d’épisodes détermine la durée et la qualité de l’apprentissage : plus il est élevé, plus l’agent aura exploré de scénarios possibles.
Au début de chaque partie, on réinitialise le jeu et on crée un dictionnaire dic_node_game qui va garder en mémoire les états rencontrés et les actions associées pendant cette partie. Ce dictionnaire est temporaire et sera utilisé plus tard pour mettre à jour les statistiques.
Pendant le déroulement du jeu, l’IA observe l’état actuel (c’est-à-dire les cartes du joueur, la carte visible du croupier et la présence d’un as utilisable). Si cet état n’a jamais été rencontré auparavant, on le crée et on l’ajoute à la liste des états découverts.
Ensuite, l’agent choisit une action à l’aide de la méthode select_learning_action() de la classe State.
L’environnement exécute alors cette action grâce à la fonction env.step(), qui renvoie le nouvel état, la récompense obtenue et des indicateurs indiquant si la partie est terminée. Si le jeu n’est pas encore fini, l’IA continue à jouer jusqu’à ce que la manche se conclue.
Quand la partie se termine, le programme affiche la récompense finale (+1.5 pour un blackjack,+1 pour une victoire, -1 pour une défaite, 0 pour une égalité). Ensuite, la phase de mise à jour commence : pour chaque couple (état, action) rencontré pendant la partie, on appelle les méthodes backtraking() sur l’état et backtracking(reward) sur l’action. Ces deux appels servent à incrémenter les compteurs de visites et à mettre à jour les valeurs de récompense moyenne. C’est ce mécanisme qui permet à l’IA d’apprendre quelles décisions mènent le plus souvent à la victoire.
Une fois toutes les parties d’entraînement terminées, l’ensemble des états et des actions explorés est sauvegardé grâce à la classe AI_saver. Cela permet de réutiliser plus tard le modèle entraîné sans devoir recommencer tout le processus.
def ai_training():
descovered_states = {}
# Utilisation de Gymnasium pour l'environnement de jeu
env = gym.make("Blackjack-v1")
n_episodes_train = ask_number("Please choose the number of game that the ai should train on")
reward = 0
for episode in range(n_episodes_train):
print("#################################################")
print(f"nouvelle épisode {episode}")
state, info = env.reset() # Nouvelle partie
reward = 0
done = False
dic_node_game = {} # Un dictionnaire State -> Action qui retient le déroulement de la partie
while not done:
if state not in descovered_states:
descovered_states[state] = State(state)
node_state = descovered_states[state]
action = node_state.select_learning_action()
dic_node_game[node_state] = action
# On joue l'action proposer par l'IA et récupère le retour de l'environnement
next_state, reward, terminated, truncated, info = env.step(action.get_order())
done = terminated or truncated
state = next_state
# en dehors du while, la partie est finie
print(f"Episode finished! Total reward: {reward}")
# On rétropropage le reward de la partie
for n_state,n_action in dic_node_game.items():
n_state.backtraking()
n_action.backtracking(reward)
ai_saver.save(descovered_states,game_name,n_episodes_train)
env.close()
Pour éviter de devoir réentraîner une intelligence artificielle à chaque exécution, une partie essentielle du projet consiste à pouvoir sauvegarder et recharger une IA déjà entraînée. C’est exactement le rôle de la classe AI_saver, qui s’appuie sur le module Pickle de Python. L’objectif est de rendre la gestion des IA simple, pratique et flexible, tout en permettant de conserver plusieurs versions d’un même modèle.
Le fonctionnement général est le suivant : lorsqu’une IA termine sa phase d’apprentissage, l’utilisateur peut la sauvegarder dans un dossier spécial nommé .ai_saves. À ce moment-là, le programme lui demande de choisir un nom pour la retrouver plus facilement par la suite. Le fichier est ensuite automatiquement complété par la date et l’heure de la sauvegarde, ainsi que par le nombre d’épisodes d’entraînement effectués. Cela donne des noms de fichiers à la fois uniques et informatifs, comme par exemple blackjack_ai_test_02-11-2025--17:30_trained_5000_times.plk.
Si le dossier n’existe pas encore, il est créé automatiquement grâce à os.makedirs. Une fois le nom final prêt, l’objet représentant l’IA est sauvegardé dans un fichier binaire grâce à la fonction pickle.dump().
Pickle est un module standard de Python qui permet de sérialiser et désérialiser des objets. La sérialisation, c’est le processus qui consiste à transformer un objet Python (par exemple une instance de classe contenant des dictionnaires, des listes et même d’autres objets) en une suite d’octets. Ces octets peuvent ensuite être enregistrés dans un fichier ou envoyés à travers un réseau. La désérialisation, c’est l’opération inverse : à partir du fichier binaire, Pickle reconstitue exactement l’objet d’origine, avec toutes ses valeurs, sa structure et son état interne.
Concrètement, quand on écrit pickle.dump(ai, f), Pickle parcourt récursivement tous les attributs de l’objet ai, traduit leur contenu en une forme binaire, et les écrit dans le fichier ouvert en mode wb (write binary). Lors du chargement avec ai = pickle.load(f), le module lit ces mêmes octets et reconstruit un objet Python identique à celui qui avait été sauvegardé, en restaurant toutes les références et les valeurs. C’est ce qui permet de retrouver une IA exactement dans l’état où elle était après son apprentissage, comme si elle n’avait jamais été arrêtée.
Il faut cependant noter que Pickle est spécifique à Python. Les fichiers produits ne sont pas lisibles directement par d’autres langages, et il ne faut pas charger un fichier Pickle provenant d’une source non fiable, car le processus de désérialisation peut exécuter du code malveillant.
La méthode load() de la classe AI_saver permet de restaurer une IA précédemment sauvegardée. Elle commence par lister tous les fichiers disponibles dans le dossier .ai_saves, éventuellement filtrés selon le nom du jeu, comme "blackjack". Cette recherche se fait grâce à la fonction list_files(), qui utilise le module glob pour parcourir les fichiers avec l’extension .plk.
Le programme affiche ensuite la liste des fichiers trouvés et demande à l’utilisateur de choisir celui qu’il souhaite recharger. Une fois la sélection faite, le fichier est ouvert en lecture binaire et passé à pickle.load(), qui reconstruit l’objet complet en mémoire. L’IA ainsi rechargée est ensuite renvoyée pour être utilisée dans les autres fonctions du programme, comme la visualisation ou la comparaison de stratégies.
Ce système de sauvegarde et de restauration rend la gestion des intelligences artificielles bien plus simple. Il devient possible d’entraîner plusieurs modèles différents, de les comparer entre eux ou de reprendre l’apprentissage là où on s’était arrêté, sans perte de données.
import pickle
from datetime import datetime
import glob
import os
import sys
# retourne tous les fichiers dans le directory qui contiennent substring ou tous si None
def list_files(directory, substring=None):
all_files = glob.glob(os.path.join(directory, "*.plk"))
all_files = [f for f in all_files if os.path.isfile(f)]
if substring:
all_files = [f for f in all_files if substring in os.path.basename(f)]
return all_files
def ask_number_in_list(msg, values_list):
while True:
try:
val = int(input(f"{msg} {values_list} : "))
if val in values_list:
return val
else:
print(f"Wrong input. Please choose beetween {values_list}.")
except ValueError:
print("Invalid input. Please choose a number.")
class AI_saver:
folder_name = ".ai_saves"
def __init__(self):
pass
def save(self,ai,game_name="no_specified",nb_training=None):
# construction du nom du fichier
now = datetime.now()
result = input("Choose a name to find more easely your ai :")
name = self.folder_name+"/"+game_name+"_ai_"+result # nom de base du fichier
name = name + "_" + now.strftime("%d-%m-%Y--%H:%M") # on ajoute la date
# ajout du nombre d'entrainement eventuellement ainsi que l'extension du fichier
if nb_training is None :
name += "_no_training_given.plk"
else:
name += "_trained_"+str(nb_training)+"_times.plk"
# Création du dossier si nécessaire
os.makedirs(os.path.dirname(name), exist_ok=True)
with open(name, "wb") as f:
pickle.dump(ai,f)
print(f"the ai as been save under the name {name}")
def load(self,game_name=None):
availables_files = list_files(self.folder_name,game_name)
if len(availables_files) == 0:
print("files not found : exiting")
sys.exit()
choices = []
print("here is the list of file found with their number choice:")
for i in range(len(availables_files)):
choices.append(i)
print(f"choice {i} : {availables_files[i]}")
choice = ask_number_in_list("select the ai you want to restore : ",choices)
print(f"You have been select the file {availables_files[choice]}")
with open(availables_files[choice], "rb") as f:
ai_loaded = pickle.load(f)
return ai_loaded
Une fois l’intelligence artificielle entraînée et sauvegardée, il est important de pouvoir évaluer ses performances et de les comparer à d’autres stratégies. C’est exactement le rôle de la fonction methods_comparaison(). Elle permet de mesurer, sur un grand nombre de parties, à quel point notre IA joue mieux qu’un joueur aléatoire ou qu’une stratégie classique de croupier.
Le principe est simple : on recharge d’abord une IA déjà entraînée puis on fait jouer trois « joueurs » différents sur le même environnement de Blackjack. Le premier est l’IA, le deuxième représente le comportement typique d’un croupier (tirer une carte quand la main est de 16 ou moins, et s’arrêter sinon), et le troisième joue complètement au hasard, en choisissant aléatoirement entre « hit » et « stand ».
Pour chacun de ces joueurs, le programme lance une série de parties, dont le nombre est défini par l’utilisateur. À chaque tour, il enregistre les résultats dans un dictionnaire qui compte le nombre de victoires, de défaites, d’égalités et la somme totale des récompenses. Ces statistiques sont mises à jour grâce à la fonction count_stats(), qui ajoute +1 dans la catégorie correspondante selon le résultat de la partie et cumule le score total pour calculer une moyenne à la fin.
Pendant les tests, l’IA joue de manière purement déterministe grâce à la méthode select_operating_action() de la classe State, c’est-à-dire qu’elle choisit toujours l’action qu’elle estime la meilleure, sans aucune exploration. Cette approche permet d’évaluer objectivement la qualité de son apprentissage, sans l’influence du hasard. En revanche, le joueur aléatoire sert de référence minimale, et la stratégie du croupier donne une idée de la performance moyenne d’un joueur humain raisonnable.
Une fois toutes les parties jouées, le programme affiche un récapitulatif complet des résultats pour les trois stratégies. Il calcule les pourcentages de victoires, de défaites et d’égalités, ainsi que la récompense moyenne obtenue. Ce dernier indicateur est particulièrement important, car il reflète le gain moyen attendu à long terme.
Grâce à cette comparaison, on peut évaluer objectivement l’efficacité de l’IA. Si elle dépasse largement les deux autres méthodes, cela signifie que son apprentissage a été efficace et qu’elle a bien intégré les stratégies gagnantes du Blackjack. Ce type de test permet aussi d’ajuster le nombre d’épisodes d’entraînement nécessaires ou de vérifier si le modèle commence à surapprendre (c’est-à-dire à trop s’adapter à des cas spécifiques).
def count_stats(dic,value):
if value>0:
dic["win"] += 1
elif value<0:
dic["lose"] += 1
else:
dic["draw"] += 1
dic["total"] += value
def methods_comparaison():
descovered_states = ai_saver.load(game_name)
env = gym.make("Blackjack-v1")
n_episodes_train = ask_number("Please choose the number of game that the ai and methods should play")
# plein de partie de l'ia
ai_stats = {"win":0,"draw":0,"lose":0,"total":0}
for _ in range(n_episodes_train):
state, info = env.reset()
done = False
while not done:
if state not in descovered_states:
descovered_states[state] = State(state)
node_state = descovered_states[state]
action = node_state.select_operating_action()
next_state, reward, terminated, truncated, info = env.step(action.get_order())
done = terminated or truncated
state = next_state
count_stats(ai_stats,reward)
print("ai's games finished")
# Stratégie du dealer (« hit » si <= 16 « stand » sinon)
dealer_stats = {"win":0,"draw":0,"lose":0,"total":0}
for _ in range(n_episodes_train):
state, info = env.reset()
done = False
while not done:
hand,a,b = state
if hand>16:
action = 0
else:
action = 1
next_state, reward, terminated, truncated, info = env.step(action)
done = terminated or truncated
state = next_state
count_stats(dealer_stats,reward)
print("dealer's strategie games finished")
# Choix aléatoire entre « hit » et « stand » à chaque fois
random_stats = {"win":0,"draw":0,"lose":0,"total":0}
for _ in range(n_episodes_train):
state, info = env.reset()
done = False
while not done:
if random.uniform(0,1) >= 0.5:
action = 0
else:
action = 1
next_state, reward, terminated, truncated, info = env.step(action)
done = terminated or truncated
state = next_state
count_stats(random_stats,reward)
# affichage des résultats et des différentes statistiques
print(f"Based on the {n_episodes_train} games here's our results :")
print(f" Ai : {round(ai_stats["win"]*100/n_episodes_train,2)} % of win; {round(ai_stats["draw"]*100/n_episodes_train,2)} % of draw; {round(ai_stats["lose"]*100/n_episodes_train,2)} % of lose; for a reward average of {round(ai_stats["total"]/n_episodes_train,5)}")
print(f"Dealer : {round(dealer_stats["win"]*100/n_episodes_train,2)} % of win; {round(dealer_stats["draw"]*100/n_episodes_train,2)} % of draw; {round(dealer_stats["lose"]*100/n_episodes_train,2)} % of lose; for a reward average of {round(dealer_stats["total"]/n_episodes_train,5)}")
print(f"Random : {round(random_stats["win"]*100/n_episodes_train,2)} % of win; {round(random_stats["draw"]*100/n_episodes_train,2)} % of draw; {round(random_stats["lose"]*100/n_episodes_train,2)} % of lose; for a reward average of {round(random_stats["total"]/n_episodes_train,5)}")
env.close()
Une fois l’intelligence artificielle entraînée, il est essentiel de pouvoir observer son comportement en situation réelle et d’interagir directement avec elle pour comprendre la logique de ses décisions. C’est tout l’intérêt des parties du programme dédiées à la visualisation et à l’interprétation des choix de l’IA. L’idée est de permettre à l’utilisateur non seulement de voir comment l’IA applique ce qu’elle a appris, mais aussi de lui poser des questions comme à un véritable joueur expérimenté.
Lorsqu’on lance la phase de visualisation, l’IA précédemment sauvegardée est rechargée depuis le disque à l’aide du module de gestion des modèles. Le programme crée alors un environnement de jeu Blackjack grâce à la bibliothèque Gymnasium, configuré en mode graphique afin que le déroulement de chaque partie soit affiché à l’écran. L’utilisateur choisit combien de parties il souhaite observer, et l’IA se met à jouer automatiquement en prenant ses décisions selon la stratégie qu’elle a apprise. Chaque état rencontré pendant la partie — c’est-à-dire la somme des cartes du joueur, la carte visible du croupier et la présence éventuelle d’un as compté comme 11 — est analysé par le modèle. L’IA choisit ensuite la meilleure action possible selon ses connaissances, qu’il s’agisse de rester ou de tirer une nouvelle carte. Un léger délai entre chaque action rend la progression plus fluide et permet de suivre clairement la logique du jeu.
Ce système offre une fenêtre graphique sur le fonctionnement interne de l’intelligence artificielle. Plutôt que de se limiter à des statistiques, on peut visualiser ses choix, constater son comportement face à des situations critiques et voir comment elle adapte sa stratégie en fonction des circonstances. Il devient alors possible d’évaluer intuitivement la cohérence de son apprentissage : si elle prend les bonnes décisions, si elle évite les risques inutiles ou au contraire s’aventure trop souvent à tirer une carte supplémentaire.
En parallèle, le programme permet aussi une interaction directe avec l’IA à travers une interface textuelle où l’utilisateur peut lui demander conseil. On indique simplement les informations de la main en cours — la somme totale de ses cartes, la carte visible du croupier et la présence ou non d’un as utilisable — et l’IA répond en proposant l’action qu’elle estime la plus judicieuse. Derrière cette simplicité, elle exploite exactement la même logique que lorsqu’elle joue seule : elle identifie l’état correspondant dans sa mémoire et applique la politique optimale qu’elle a construite durant son apprentissage. Si la situation demandée n’a jamais été rencontrée, l’IA prévient qu’elle ne connaît pas la réponse, ce qui traduit bien la limite naturelle de tout apprentissage basé sur l’expérience.
def blackjack_visual():
descovered_states = ai_saver.load(game_name)
dt = 0.7 # Délai entre deux actions pour faciliter l’observation de l’IA (en secondes)
env = gym.make("Blackjack-v1",render_mode="human")
n_episodes_train = ask_number("Please choose the number of game that the ai should play")
for _ in range(n_episodes_train):
state, info = env.reset()
done = False
while not done:
if state not in descovered_states:
descovered_states[state] = State(state)
node_state = descovered_states[state]
action = node_state.select_operating_action()
next_state, reward, terminated, truncated, info = env.step(action.get_order())
done = terminated or truncated
state = next_state
time.sleep(dt)
env.close()
def ai_suggestion():
descovered_states = ai_saver.load(game_name)
done = False
while not done:
choice = ask_number_in_list("select 0 to get the ai response or 1 to exit",[0,1])
if choice == 1:
done = True
else:
player = ask_number("please enter the sum of your cards")
dealer = ask_number("please enter dealer's cards")
ace = ask_number("please enter 1 if you have a playable ace (count as 11) or 0 otherwise")
state = player,dealer,ace,
if state not in descovered_states:
print("The ai don't know the solution for this case")
else:
node_state = descovered_states[state]
action = node_state.select_operating_action()
print(f"Knowing that a 0 means a stay and a 1 a hit, the ai recommands : {action.get_order()}")
Le Q-Learning est un algorithme d’apprentissage par renforcement qui permet à un agent d’apprendre une politique optimale en interagissant avec son environnement. L’idée est d’apprendre une table de valeurs Q(s,a), où :
Q(s,a) représente la valeur d’une action a dans un état s.
L’agent met à jour cette table en utilisant la récompense immédiate et une estimation de la valeur future des états.
Le problème de Mountain Car est que ses états sont continus (position et vitesse réelles).
Mais le Q-Learning repose sur une table Q discrète : il faut donc convertir les valeurs continues en indices entiers.
Pour cela, on divise chaque dimension de l’espace des états en un certain nombre de bacs (bins).
Par exemple :
Si n_bins = (20, 16), cela signifie :
La position est découpée en 20 intervalles
La vitesse est découpée en 16 intervalles
Cela donne une table Q de taille 20 * 16 * 3 (car 3 actions possibles)
Plus les intervalles sont nombreux :
plus l’approximation de l’espace est fine, et donc on aura une meilleure précision,
mais la table Q devient plus grande donc l'apprentissage prend plus de temps
Pour chaque épisode, l’agent interagit avec l’environnement en choisissant des actions selon une stratégie ϵ -gloutonne.
À chaque étape, la table Q est mise à jour selon la formule du Q-Learning.
rewards_per_episode = [] # tableau pour stocker le reward de chaque épsiode (uniquement visuel)
for episode in range(n_episodes):
state, info = env.reset()
state = agent.discretize_state(state) # Discrétisation de l'état initial
done = False
total_reward = 0
while not done:
action = agent.get_action(state) # Stratégie epsilon-gloutonne
next_state, reward, terminated, truncated, info = env.step(action) # Exécution de l'action
next_state = agent.discretize_state(next_state) # Discrétisation
agent.update(state, action, reward, next_state, terminated) # Mise à jour de la table Q
state = next_state # Passage à l'état suivant
total_reward += reward
done = terminated or truncated
agent.decay_epsilon() # Décroissance de epsilon
rewards_per_episode.append(total_reward) # Ajout du reward de cet épisode
env.close()
# Visualisation de l'apprentissage sous forme de graphe:
window = 100
moving_avg = np.convolve(rewards_per_episode, np.ones(window) / window, mode="valid")
plt.plot(moving_avg)
plt.title("MountainCar - Moyenne des récompenses")
plt.xlabel("Épisodes")
plt.ylabel("Récompense moyenne")
plt.show()
Discrétisation : on découpe l’espace continu des états pour l’adapter au Q-Learning, le paramètre n_bins : définit la résolution de cette discrétisation.
Exploration/Exploitation : au début, l’agent explore beaucoup (ϵ grand), puis il exploite ce qu’il a appris.
Récompenses : elles sont toujours négatives ce qui fait que l’agent apprend à atteindre le drapeau le plus vite possible.
def choose_action(self, state, epsilon):
if random.uniform(0,1) < epsilon:
return random.randint(0, 1) # action aléatoire
else:
state_disc = self.discretize(state)
return np.argmax([self.get_q(state_disc, a) for a in [0,1]])

-v1.png)
-v2.png)
-v4.png)




{kind=link}
{kind=link}
{kind=link}